Explicabilité de l’Intelligence Artificielle
Pourquoi, pour qui ?
L’Intelligence Artificielle (IA) permet d’exploiter des volumes de données considérables afin de réaliser des tâches complexes, généralement de manière très efficace. Cependant, les modèles d’IA et plus précisément de Machine Learning, voire de Deep Learning, sont souvent comparés à des « boîtes noires » du fait de leur fonctionnement opaque, pas forcément compréhensible par les humains. La complexité de ces modèles est donc une force car elle permet de répondre à des problèmes mieux qu’avec des modèles plus simples, mais c’est aussi une faiblesse puisque cela les rend peu interprétables. Or, dans certains domaines critiques tels que le diagnostic médical ou la conduite autonome, où des vies humaines peuvent être en jeu, le contrôle et la compréhension de mécanismes de décision de ces modèles sont indispensables.
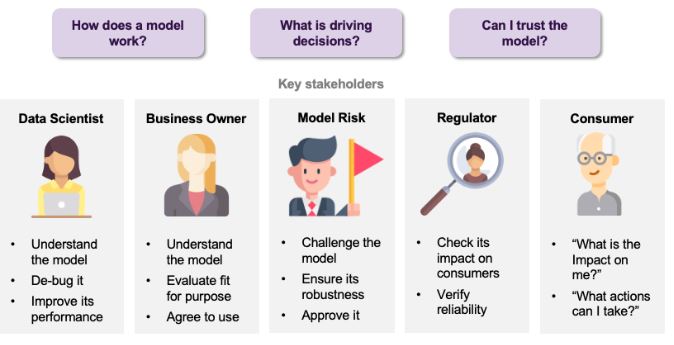
L’explicabilité ou l’interprétabilité de l’IA vise à rendre le fonctionnement et les résultats des modèles davantage intelligibles et transparents pour les humains, sans pour autant faire de compromis sur les performances. Ce besoin d’explicabilité concerne différents acteurs, ayant chacun leurs motivations. Dans un premier temps, pour le Data Scientist qui développe le modèle, une meilleure compréhension peut permettre de corriger certains problèmes et d’améliorer le modèle. Côté business, l’explicabilité peut être un moyen d’évaluer l’adéquation du modèle avec la stratégie et l’objectif de l’entreprise. L’explicabilité peut également avoir pour but de mettre à l’épreuve le modèle afin de vérifier sa robustesse, sa fiabilité et son impact éventuel sur les clients. Enfin, cela peut permettre au client qui serait l’objet d’une décision d’un système basé sur un modèle d’IA d’être informé de l’impact de cette décision et des potentielles actions possibles pour la modifier.
Avec le développement croissant des techniques d’intelligence artificielle, la question de l’explicabilité est devenue un défi majeur pour leur adoption à grande échelle. De nombreuses méthodes d’explicabilité existent et voient encore le jour actuellement, certains critères permettent de les distinguer. D’abord, ces méthodes peuvent avoir différents buts, notamment expliquer un modèle boîte noire (explicabilité post-hoc) ou créer un modèle interprétable (explicabilité intrinsèque), mais aussi vérifier l’équité d’un modèle ou tester la sensibilité de ses prédictions. Ensuite, la portée des explications produites peut être locale si elles concernent une prédiction en particulier, ou globale si elles portent sur le comportement général du modèle. De plus, certaines méthodes sont spécifiques à un type de modèle alors que d’autres en sont agnostiques, elles s’appliquent à tout type de modèle. Enfin, de la même façon, une méthode peut s’appliquer à un ou plusieurs types de données : tabulaires, images, texte…
Comment ça marche ?
Afin de présenter quelques méthodes et leur application, un exemple concret et simple est utilisé : prédire la résiliation de clients d’un opérateur télécom. Le jeu de données, Telco Customer Churn [2], comprend environ 7000 clients décrits par une vingtaine de variables (informations personnelles, services souscrits…), dont la résiliation (oui/non). Il s’agit donc d’un problème de classification binaire sur des données tabulaires. À la suite de l’analyse exploratoire et du pré-traitement des données, un modèle de Machine Learning (random forest) est entraîné sur une partie des données, l’échantillon d’apprentissage, et l’évaluation des performances est réalisée sur les données restantes, l’échantillon de test. Afin de mieux comprendre les décisions prises par le modèle, il est possible d’appliquer des méthodes d’explicabilité. Les méthodes qui vont être présentées ici sont locales, elles permettent donc d’expliquer la décision du modèle, résiliation ou non, concernant un client en particulier. Le client choisi pour illustrer les différentes méthodes est une femme, ayant souscrit un contrat mensuel depuis un peu plus d’un an. Le modèle a correctement prédit la résiliation de ce client.
LIME : Local Interpretable Model-agnostic Explanations [3]
Une des méthodes d’explicabilité la plus populaire est LIME (Local Interpretable Model-agnostic Explanations). Son principe est simple : approximer localement le modèle complexe par un modèle plus simple et donc interprétable. Cette méthode permet d’expliquer la décision du modèle concernant une observation particulière, ici un client. De nouvelles instances proches de cette dernière sont générées en perturbant les valeurs des variables. Ces nouvelles instances sont pondérées selon leur proximité à l’instance à expliquer. Les prédictions sont ensuite réalisées pour ces nouvelles instances. Un modèle simple, par exemple une régression linéaire, est finalement ajusté sur ces nouvelles instances et les prédictions associées afin de produire l’explication.
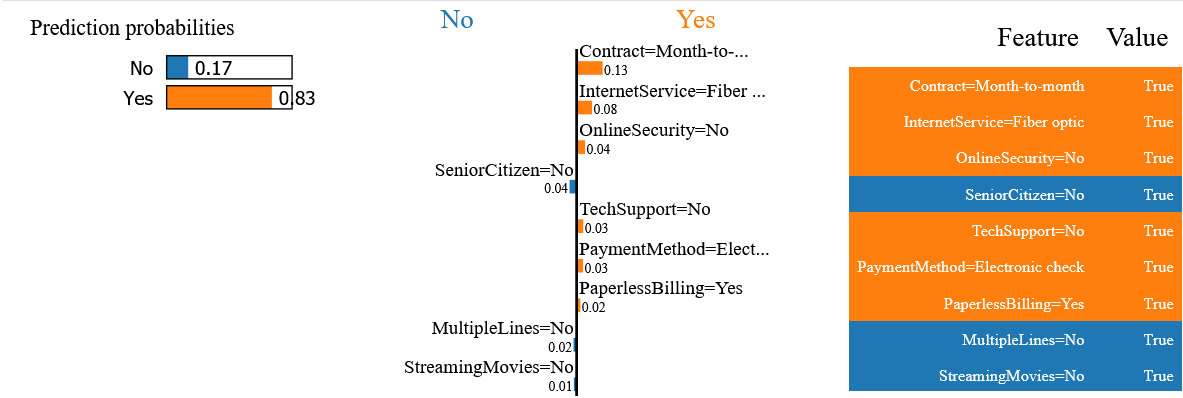
Pour le client choisi, l’explication fournie par la méthode LIME indique que la probabilité de résiliation est de 83% et que cette prédiction est influencée de manière positive notamment par le fait que ce client ait souscrit un contrat mensuel avec la fibre optique.
Ancres [4]
La méthode des ancres (Anchors) a été développée pour pallier certains problèmes de LIME, notamment concernant la capacité de généralisation des explications, qui n’est pas clairement définie. Le principe de cette deuxième méthode est de définir des règles de décisions qui ancrent une prédiction, grâce à un algorithme de recherche optimisé.
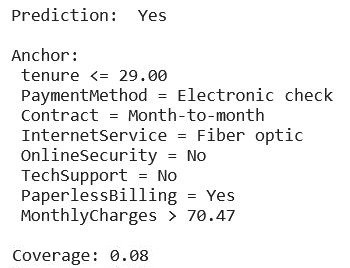
L’explication fournie concernant le client choisi indique les variables qui ancrent la prédiction de résiliation : une ancienneté plutôt faible (inférieure à 29 mois), un type de paiement électronique, un contrat mensuel … La plus-value de cette méthode est liée à une information supplémentaire, la couverture. Elle décrit la part d’observations qui vérifie l’ancre, ici 8% des clients possèdent les caractéristiques définies par l’ancre.
Explications contrefactuelles [5]
A l’inverse de la méthode précédente qui se focalise sur les variables qui ancrent les prédictions, la méthode des explications contrefactuelles recherche celles dont le changement permet de modifier la prédiction. Plusieurs approches existent pour trouver le plus petit changement possible qui modifie la prédiction, notamment l’approche naïve par essai et erreur ou encore l’utilisation d’un algorithme d’optimisation. L’avantage de cette méthode est qu’elle génère plusieurs explications pour une seule décision.

Toujours concernant le client choisi, une première explication contrefactuelle consiste en la modification de son type de contrat et de son type de paiement, avec ces deux changements, le modèle prédit la non-résiliation. Il en va de même si uniquement son ancienneté est modifiée, de 13 à 65 mois.
Ainsi, ces trois méthodes produisent des explications différentes mais qui semblent cohérentes entre elles puisque certaines variables se retrouvent dans les toutes les explications. C’est le cas du type de contrat, qui semble être un facteur important pour la prédiction. Cela paraît pertinent puisqu’il est généralement plus simple de résilier un contrat mensuel, souvent sans engagement.
Et après ?
Ce cas d’utilisation simple a permis d’illustrer quelques méthodes d’explicabilité locales dans le cas d’un problème de classification binaire sur des données tabulaires. De nombreuses autres méthodes existent et permettent de traiter divers types de problématiques, de modèles et de données. Par exemple, dans le domaine de la conduite autonome, certaines méthodes permettent d’analyser les prédictions d’un détecteur d’objet pour savoir sur quel(s) endroit(s) de l’image il se focalise.

(sur la première ligne : bonne détection en vert, mauvaise détection en rouge)
Ainsi, les différentes méthodes d’explicabilité peuvent permettre d’identifier des problèmes et comportements inattendus sur un modèle, ou encore de comparer des modèles entre eux. S’il est envisageable de définir une stratégie d’utilisation de ces méthodes d’explicabilité selon différents critères, il est plus compliqué de mettre en place une méthode générale permettant d’utiliser leurs résultats dans le cadre du test de systèmes basés IA. En effet, les problématiques, données et modèles d’IA sont divers. De plus, les attentes en termes d’explicabilité ne sont pas forcément claires (comment définir le bon comportement d’un modèle sans spécifications détaillées ?) et leur interprétation peut demander des compétences spécifiques au domaine en question.
Finalement, les méthodes d’explicabilité sont variées, tant concernant les techniques utilisées que la visualisation et le type d’explication. Une des difficultés réside donc dans l’évaluation de ces méthodes. Il est cependant possible de définir des critères pour les comparer et de s’intéresser à leurs avantages et inconvénients respectifs. Ces critères peuvent permettre de choisir la/les méthode(s) adaptée(s) à un cas d’usage. Dans le cadre du test des systèmes IA, Kereval s’intéresse à l’utilisation de ces méthodes comme outil supplémentaire d’analyse des modèles.
Sur le même sujet :
- Article sur la vérification formelle de l’IA
- Webinar « Comment tester une IA » – La taverne du testeur