Équité et Intelligence Artificielle : Les Enjeux de la Fairness dans les tests
Les femmes sont-elles mal considérées par ChatGPT ?
Saviez-vous qu’en France en 2023, l’Ordre des Médecins estime que la parité a été atteinte parmi les généralistes (1,2) ? Les femmes seront même majoritaires dans les prochaines années. Pourtant, voici cinq requêtes soumises à la suite à ChatGPT en juin 2023.

Systématiquement les phrases complétées par ChatGPT établissaient une hiérarchie. La femme occupait alors une fonction qui peut être perçue comme socialement inférieure. À l’inverse, l’homme était placé au même niveau que son homologue. Ces réponses ne concordaient pas avec la réalité qui est la nôtre. Ce comportement traduit un problème de Fairness, les réponses du modèle étaient discriminantes envers les femmes. C’est pourquoi les dernières versions de ChatGPT ont été corrigées. Détaillons les mécanismes qui peuvent expliquer un tel phénomène.
Intelligence artificielle et données
ChatGPT est un modèle de Machine Learning (ML), une branche de l’Intelligence Artificielle (IA) comme FaceID ou encore Alexa. Tous ces outils sont de plus en plus ancrés dans notre réalité. Leur développement s’accélère encore depuis quelques mois. Les enjeux sont immenses car l’IA est répandue dans les systèmes critiques (la voiture autonome, l’imagerie médicale, l’aviation) et leur impact direct sur la vie des individus est grandissant.
Les modèles de ML s’appuient sur un entrainement à partir de jeux de données. Ces données sont alors constituées de variables et d’un label. Le modèle va « apprendre » les liens entre ces différentes variables et le label. Après la phase d’entrainement, fournir au modèle les variables d’une donnée permet d’estimer les chances que le label associé soit tel ou tel résultat. Le processus d’apprentissage nécessite donc d’importantes quantités de données pour rendre le modèle performant. C’est pourquoi, les jeux de données utilisés doivent être aussi étoffés que possible. Cependant la quantité ne suffit pas, la notion de représentation est primordiale. Le jeu de données doit représenter du mieux possible la réalité relative au problème que le modèle devra traiter. Dans le cas contraire, le jeu de données est biaisé et l’IA devient imprécise. C’est ce qui peut expliquer les exemples présentés plus haut. Actuellement (Octobre 2023), il est toujours possible de faire ressortir ce biais avec des requêtes en anglais contenant le terme « a doctor », que ChatGPT comprendra la plupart du temps comme un homme médecin…
Biais et Fairness
Les biais font référence aux distorsions systématiques et/ou aux préférences subjectives qui influent sur la perception et l’interprétation des informations. Les biais dans les données (dont on ne peut jamais totalement s’affranchir tant il en existe de sortes) impactent directement le comportement de l’IA. Le modèle n’est alors pas Fair et il produit des résultats eux-mêmes biaisés.
La Fairness est le domaine de recherche du ML dont l’objectif est l’évaluation et l’atténuation des discriminations engendrées par les résultats d’un modèle.
Le terme de « Fairness » pourrait se traduire imparfaitement par l’Éthique ou l’Équité, dont les sens respectifs restent assez flous. Il n’en existe pas de définition universelle. D’après l’AltAI (3), « la Fairness fait référence à une variété d’idées comme l’équité, l’impartialité, l’égalitarisme, la non-discrimination, ou la justice. La Fairness incarne un idéal d’égalité de traitement entre les individus et entre les groupes d’individus. […] Mais la Fairness englobe aussi un aspect procédural, c’est la capacité de chercher et de trouver de l’aide lorsque des droits individuels et des libertés sont violés. »
L’IA et son impact direct sur la vie d’individus
Si les exemples précédents sont plutôt inoffensifs, ces résultats biaisés peuvent drastiquement impacter la vie de certaines personnes. En 2016, la justice américaine teste COMPAS (Correctional Offender Management Profiling for Alternative Sanctions), une IA qui fournit un score de récidive des délinquants. Cet outil est mis à disposition des juges à titre indicatif au moment où ils peuvent remettre en liberté ces condamnés.
Rapidement les performances de ce système basé IA sont pointées du doigt et plus spécifiquement les différences de traitement des individus par rapport à leur couleur de peau (4). Les scores de récidive assignés aux personnes noires sont en moyenne plus élevés que ceux d’un individu blanc de profil criminel comparable.

Après deux ans d’utilisation, le comportement des remis en liberté peut être analysé. Les prédictions faites par COMPAS peuvent être confrontées aux vérités de terrain, à savoir, le criminel a-t-il récidivé ou non ? Le modèle a prédit correctement les récidivistes dans 60% des cas. Pourtant, les personnes noires ont quasiment deux fois plus de chance que les personnes blanches d’être labelisées « haut risque » et de ne pas récidiver. Inversement, Les personnes blanches ont quasiment deux fois plus de chance que les noires d’être labélisées « bas risque » et de récidiver.
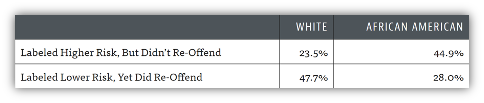
Ces résultats confirment que COMPAS discrimine les individus selon leur couleur de peau. Les populations noires étant généralement plus contrôlées par la police, elles sont par conséquent plus fréquemment arrêtées et enfermées pour des délits de gravité moindre. C’est un biais important ! Les deux groupes ne sont pas représentés par des personnes de casier judiciaire en moyenne identique (entre autres) et donc le modèle traite les deux groupes différemment.
L’effet redlining
À ce stade, peut-être vous posez vous cette question : Si indiquer au modèle l’appartenance des individus à des groupes sociaux crée des discriminations, pourquoi ne pas tout simplement retirer les variables sensibles de notre jeu de données ? En effet, si le modèle n’a pas accès à l’origine des individus (ou à n’importe quelle variable sensible comme le genre, l’âge, la religion, etc.) on peut penser qu’il ne pourra pas discriminer ces groupes.
Cette idée est pourtant à proscrire. En éliminant purement et simplement l’attribut sensible, au mieux aucun problème n’aura été résolu, au pire le modèle deviendra incohérent, ses résultats seront complètement faux et sans intérêt pratique.
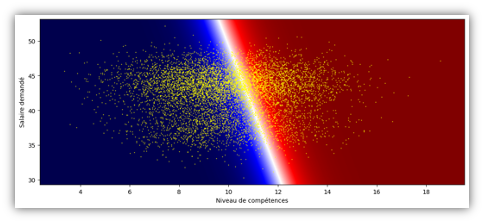
La figure 3 permet de visualiser la frontière de décision d’un modèle qui recrute des candidats selon différents critères. Chaque point représente un candidat qui est placé sur le graphique en fonction d’une note globale de ses compétences et du salaire qu’il demande. Ce sont les variables du jeu de données. Une troisième variable était disponible, le genre du candidat, qui a été retiré pour tenter d’éviter les discriminations. La frontière blanche coupe l’espace en deux. Les points sur fond rouge représentent les candidats que le modèle choisi de recruter et en bleu les recalés. L’inclinaison de la frontière permet de visualiser que le modèle sélectionne parmi les candidats de même niveau, ceux qui demandent un salaire plus élevé. Ce comportement ne respecte pas les règles métier et ces résultats n’ont donc aucune valeur. C’est une conséquence d’avoir retirer l’accès au modèle à l’attribut de genre.
En fait, dans un jeu de données, les différentes variables sont corrélées entre elles, par exemple, on peut s’attendre à ce qu’en moyenne être une femme se traduise par une taille, un poids ou une pointure plus petite. Très souvent, même sans avoir directement accès à l’appartenance à un groupe, un modèle IA est capable de déterminer cette caractéristique indirectement à partir de toutes les autres informations à sa disposition. C’est l’effet redlining. Pour cette raison s’affranchir de l’attribut sensible ne permet généralement pas d’éviter les discriminations du modèle.Pire, lorsque les groupes sont très différents, cette simplification du jeu de données entraine des confusions. Le modèle n’a alors plus les moyens de tirer des conclusions pertinentes et propose des résultats qui ne s’accordent plus avec l’expression du besoin initial.
Métriques de Fairness
Il existe de nombreuses métriques de Fairness dont le but consiste à fournir une mesure de la différence de résultat et/ou de performance à l’échelle des individus ou des groupes d’individus (5). Le choix de la métrique dépend du type de problème et de certaines caractéristiques (légalité, répartition des groupes de population) mais aussi de l’objectif visé (6). Une priorité peut être faite afin que des individus de groupes différents soient traités de la même manière dans le cas où ils ont des profils similaires. À contrario, on peut préférer recruter les meilleurs 20% des candidats du groupe A et ceux du groupe B, et ce en dépit de l’écart de niveau général des deux groupes. Les métriques de Fairness donnent donc un aperçu de l’écart de traitement les individus ou encore entre les groupes d’individus.
Méthodes d’atténuation
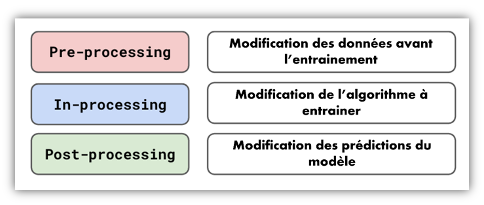
Pour réduire ces inégalités on dispose de nombreuses méthodes d’atténuation. Elles peuvent être réparties en trois groupes :
- Les méthodes Pre-processing, qui transforment le jeu de données avant l’entrainement du modèle.
- Les méthodes In-processing, qui intègrent la problématique de Fairness directement dans la structure du modèle.
- Les méthodes Post-processing, qui appliquent des corrections aux résultats produits.
Chaque méthode affecte à sa manière les métriques de Fairness. Le choix de la méthode dépend des composantes du système.
Atténuation de biais dans un cas pratique
Prenons le dataset de référence Adult UCI (University of California, Irvine) (7). Il y figure environ 40 000 données représentant chacune un individu. Chaque individu est décrit par une quinzaine de variables comme le genre, l’âge, le nombre d’heures travaillées par semaine, le secteur d’activité, etc. On distingue deux catégories. Ceux qui gagnent moins de 50 000$ par an et ceux qui sont payés plus. Ici on s’intéresse au genre comme variable sensible, c’est-à-dire que l’on va observer les différences de comportement du modèle envers le groupe des hommes et celui des femmes.
Un modèle est entrainé. Il pourra déterminer, sur la base des données, si une personne mérite un salaire de « +50K », l’issue positive, ou « -50K », l’issue négative. Une utilité, par exemple, pourrait être le développement d’un algorithme qui détermine le salaire auquel peut prétendre un individu par rapport à certains critères. Nous utiliserons un modèle basique pour ce genre de problème : une régression logistique (8).
Parmi l’ensemble des métriques disponibles, on retient la conditional statistical parity (9) sous la condition de la variable de profession. Son principe consiste à mesurer, pour un poste donné donc, la proportion des issues positives produites pour les femmes, et la comparer avec la proportion des issues positives produites pour les hommes. Un score de « 0 » indique que ces proportions sont égales pour les deux groupes, le modèle est alors parfaitement Fair selon cette métrique.
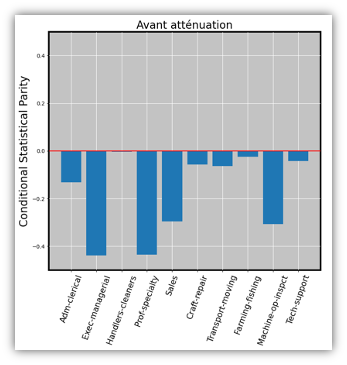
La métrique est calculée pour chaque profession représentée en nombre suffisamment conséquent dans le jeu de données. Tous les bâtons pointent vers le bas. Cela traduit que pour chacune des professions, le modèle considère que les femmes doivent être moins souvent payées « +50K » que les hommes. Pour certaines professions, on dépasse même « -0.4 », soit un écart de 40 points. Par exemple, le modèle propose que 50% des hommes « Exec-managerial » soient payés « +50K » et seulement 10% des femmes.
Pour atténuer ces disparités et revenir à un traitement moins discriminatoire des femmes, une technique d’atténuation est appliquée. Ici le choix se porte sur le prejudice remover regularizer (10), une méthode In-processing. Un terme de Fairness est intégré à la fonction coût de la régression logistisque. Voici les résultats :
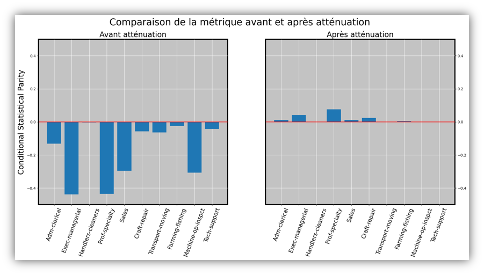
À gauche, le graphique précédent a été reporté à titre de comparaison. Après atténuation, à droite, tous nos groupes ont pour nouvelle valeur de métrique presque « 0 ». Les hommes et les femmes sont donc maintenant affectés en proportion similaire aux issues positives et négatives.
Quel avenir pour la Fairness ?
La Fairness est indéniablement un des enjeux majeurs dans le développement de systèmes IA pour ces prochaines années. Il s’agit d’une certaine forme de mesure de la performance qui est malheureusement trop facilement occultée. Elle s’inscrit parmi les axes pour le test de l’IA aux côtés de la Robustesse, de l’Explicabilité ou encore de la Sécurité, domaines dans lesquels Kereval apporte son expertise.
Les effets des biais et la Fairness sont des phénomènes complexes, qui nécessitent une attention toute particulière dès les premières phases de conception d’un algorithme. Une compréhension accrues des mécanismes en jeu est indispensable pour appréhender correctement les métriques et méthodes d’atténuation qui peuvent se révéler très abstraites.
Les discriminations algorithmiques sont également sujettes à la loi, en France, avec les lois de protection contre les discriminations et bientôt à l’échelle de l’Union Européenne avec l’AI Act (11), dont les questions autour de la Fairness sont parmi les éléments centraux.
Sur le même sujet :
- Article – Explicabilité du test de l’IA
- Article – Vérification formelle de l’IA
- Webinar « Comment tester une IA » – La taverne du testeur