Explicability of Artificial Intelligence
Why, and for whom?
Artificial Intelligence (AI) makes it possible to process vast amounts of data to perform complex tasks, generally with great efficiency. However, AI models—and more specifically machine learning and deep learning models—are often likened to “black boxes” because their inner workings are opaque and not necessarily understandable to humans. The complexity of these models is therefore a strength because it allows them to address problems more effectively than simpler models, but it is also a weakness since it makes them difficult to interpret. However, in certain critical fields such as medical diagnosis or autonomous driving, where human lives may be at stake, controlling and understanding the decision-making mechanisms of these models is essential.
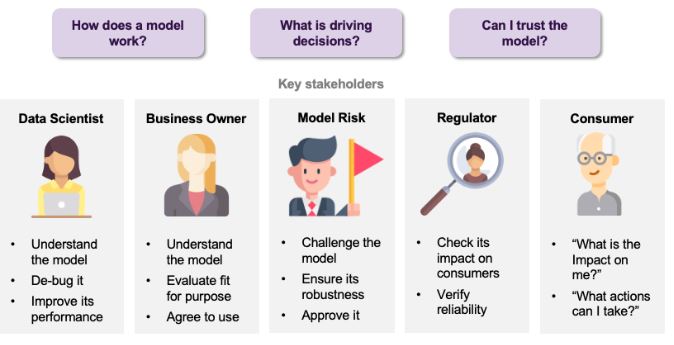
The explicability or interpretability of AI aims to make the functioning and results of models more understandable and transparent to humans, without compromising performance. This need for explicability affects various stakeholders, each with their own motivations. First, for the data scientist developing the model, a better understanding can help identify and correct certain issues and improve the model. From a business perspective, explicability can serve as a means to assess the model’s alignment with the company’s strategy and objectives. Explicability can also aim to test the model to verify its robustness, reliability, and potential impact on customers. Finally, it can allow a customer who is the subject of a decision made by a system based on an AI model to be informed of the impact of that decision and the potential actions available to modify it.
With the growing development of artificial intelligence techniques, the issue of explicability has become a major challenge to their widespread adoption. Many explicability methods exist and are still emerging today; certain criteria help distinguish them. First, these methods may have different goals, such as explaining a black-box model (post-hoc explainability) or creating an interpretable model (intrinsic explicability), but also verifying a model’s fairness or testing the sensitivity of its predictions. Second, the scope of the explanations produced can be local if they concern a specific prediction, or global if they address the model’s overall behavior. Furthermore, some methods are specific to a certain type of model, while others are model-agnostic and apply to any type of model. Finally, similarly, a method may apply to one or more types of data: tabular, images, text…
How does it work?
To illustrate a few methods and their applications, we’ll use a concrete and simple example: predicting customer churn for a telecom operator. The dataset, Telco Customer Churn [2], includes approximately 7,000 customers described by about twenty variables (personal information, subscribed services, etc.), including churn status (yes/no). This is therefore a binary classification problem on tabular data. Following exploratory analysis and data preprocessing, a machine learning model (random forest) is trained on a portion of the data—the training set—and performance evaluation is performed on the remaining data—the test set. To better understand the decisions made by the model, explicability methods can be applied. The methods presented here are local, meaning they explain the model’s decision—whether to terminate or not—regarding a specific customer. The customer chosen to illustrate the different methods is a woman who has had a monthly subscription for just over a year. The model correctly predicted this customer’s churn.
LIME : Local Interpretable Model-agnostic Explanations [3]
One of the most popular explicability methods is LIME (Local Interpretable Model-agnostic Explanations). The principle is simple: locally approximate the complex model with a simpler, and therefore interpretable, model. This method makes it possible to explain the model’s decision regarding a specific observation, in this case a customer. New instances similar to this one are generated by perturbing the values of the variables. These new instances are weighted according to their proximity to the instance to be explained. Predictions are then made for these new instances. A simple model, such as a linear regression, is finally fitted to these new instances and the associated predictions to produce the explanation.
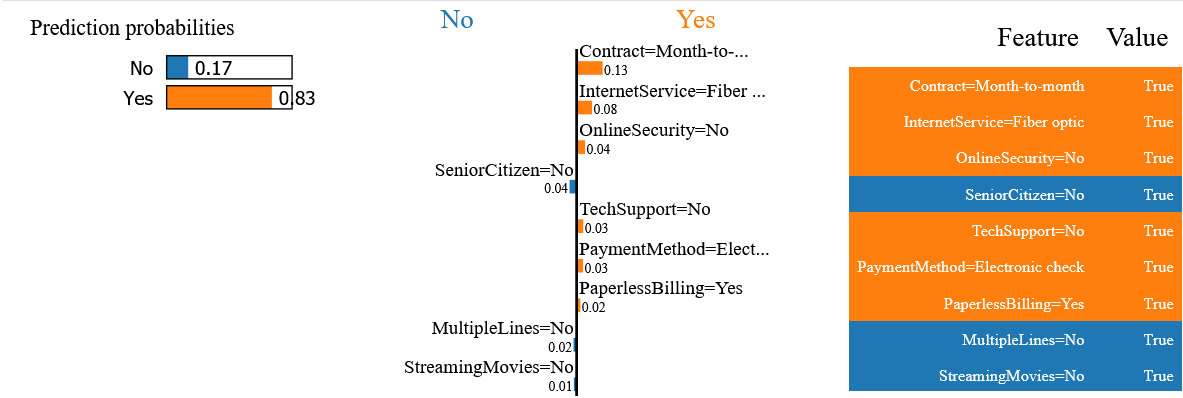
For the selected customer, the explanation provided by the LIME method indicates that the probability of churn is 83% and that this prediction is positively influenced, in particular, by the fact that this customer has signed up for a monthly fiber-optic plan.
Anchors [4]
The Anchors method was developed to address certain issues with LIME, particularly regarding the generalizability of explanations, which is not clearly defined. The principle of this second method is to define decision rules that anchor a prediction, using an optimized search algorithm.
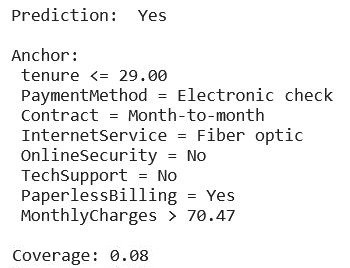
The explanation provided for the selected customer identifies the variables that anchor the churn prediction: relatively short tenure (less than 29 months), electronic payment method, monthly contract… The added value of this method lies in an additional piece of information: coverage. It describes the proportion of observations that verify the anchor; here, 8% of customers possess the characteristics defined by the anchor.
Counterfactual explanations [5]
Unlike the previous method, which focuses on the variables that underpin the predictions, the counterfactual explanation method identifies those variables whose alteration can change the prediction. Several approaches exist for finding the smallest possible change that alters the prediction, including the naive trial-and-error approach or the use of an optimization algorithm. The advantage of this method is that it generates multiple explanations for a single decision.

Still regarding the selected customer, a first counterfactual explanation involves changing their contract type and payment method; with these two changes, the model predicts that the contract will not be terminated. The same holds true if only their tenure is changed, from 13 to 65 months.
Thus, these three methods produce different explanations, but they appear consistent with one another since certain variables appear in all of the explanations. This is the case with contract type, which appears to be an important factor for prediction. This seems relevant since it is generally easier to terminate a monthly contract, which often has no commitment.
What’s next?
This simple use case has illustrated a few local explicability methods for a binary classification problem using tabular data. Many other methods exist and can be used to address various types of problems, models, and data. For example, in the field of autonomous driving, certain methods allow us to analyze the predictions of an object detector to determine which part(s) of the image it is focusing on.

(on the first row: correct detection in green, incorrect detection in red)
Thus, different explicability methods can help identify unexpected issues and behaviors in a model, or even compare models against one another. While it is possible to define a strategy for using these explicability methods based on various criteria, it is more complicated to establish a general method for utilizing their results in the context of testing AI-based systems. Indeed, AI problems, data, and models are diverse. Furthermore, expectations regarding explicability are not necessarily clear (how can one define a model’s correct behavior without detailed specifications?), and interpreting them may require domain-specific expertise.
Ultimately, there is a wide variety of explicability methods, both in terms of the techniques used and the visualization and type of explanation provided. One of the challenges, therefore, lies in evaluating these methods. However, it is possible to define criteria for comparing them and to examine their respective advantages and disadvantages. These criteria can help in selecting the method(s) best suited to a given use case. In the context of AI system testing, Kereval is exploring the use of these methods as an additional tool for model analysis.
Related topics:
- Article on formal verification of AI
- Webinar “How to Test AI” – La taverne du testeur